中亦科技黄远邦;颠覆传统调优方法的案例分享
《中亦科技黄远邦;颠覆传统调优方法的案例分享》要点:
本文介绍了中亦科技黄远邦;颠覆传统调优方法的案例分享,希望对您有用。如果有疑问,可以联系我们。
前言:
为了加快SQL语句的执行速度,你都用过哪些办法呢?我常常听到不少DBA总结道:“调优也没什么难的,常用的不就那三板斧吗:
收集表的统计信息;
给执行计划中产生全表扫的表加索引;
再不行就给语句加上并行…”
每每听到这样的说法,我倒也无法直接反驳,上面说的办法确实是我们常用的办法,但是,我深知其中涉及的知识远不止口头上说的那么简单,而是在深刻分析后得出的轻巧.
比如,如果我们看到下面的执行计划,你会觉得这里的问题大概在哪里呢?为何执行效果还是那么不如人意呢?
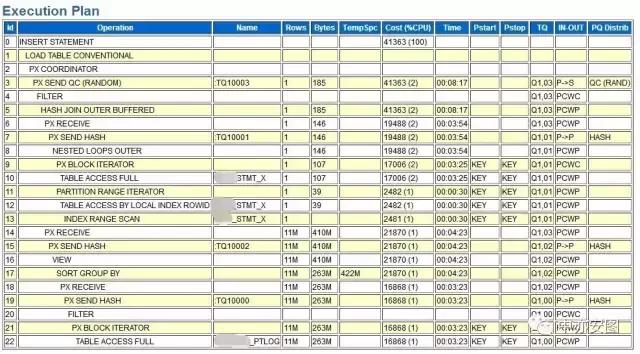
看完,我想有很多有经验的DBA一定在说,这个一看就能知道问题是在哪?而如果我告诉你这其中的问题也许并不在你以往的经验范围中时,你会打算如何进一步分析呢?
今天我们来看看CESOUG成员卞卞的分享,看他是如何来一步步分析这个问题的!如果你也曾轻易的认为,如果SQL执行缓慢,不管原因先收集统计信息,加并行,加索引总应该就能办理的话,也许这篇小文能稍稍改变你的观点;
问题来了
刚到客户现场,客户就把问题抛了出来.
“小卞工,我们批量的一个语句跑了十几个小时了,还是跑不完啊!“
”你们都干了什么,原来也这么慢吗?“
“原来也比较慢,我们想加快一下速度,于是照着网上的办法,加了索引,收集了统计信息,还加了并行,原本以为速度会大大加快的,没想到反而变慢了!”
“好吧!看来三板斧砍到了自己脚上了.”
先确认环境如下:
ORACLE 11.2.0.4 RAC (两节点)
Platform | CPUs | Cores | Sockets | Memory (GB) |
Linux x86 64-bit | 32 | 16 | 2 | 125.93 |
Begin | End | |||
Buffer Cache: | 32,256M | 32,256M | Std Block Size: | 8K |
Shared Pool Size: | 3,558M | 3,573M | Log Buffer: | 83,208K |
嗯,看起来配置还不错,看看问题是出在哪吧.
问题在哪里
SQL语句跑的慢,那自然先收一个AWRSQLRPT来看看,具体语句如下:
SELECT
...........
FROMXXX_ STMT _X T1
LEFTJOIN(SELECT P.ACCOUNT AS XACCOUNT,
P.MONTH_NBR,
... AS SHOPPING_POINT
FROMXXX_PTLOG P
WHERE P.CREATE_DATE <=SYSDATE+1
AND P.CREATE_DATE > ADD_MONTHS(SYSDATE,-12)
GROUPBY P.ACCOUNT, P.MONTH_NBR) T2
ONT1.XACCOUNT = T2.XACCOUNT
ANDT1.MONTH_NBR = T2.MONTH_NBR
LEFTJOINXXX_STMT_X T3
ONT1.XACCOUNT = T3.XACCOUNT
ANDT1.MONTH_NBR -1= T3.MONTH_NBR
ANDT3.STMT_DATE <= ADD_MONTHS(SYSDATE,-1)
ANDT3.STMT_DATE > ADD_MONTHS(SYSDATE,-13)
WHERET1.STMT_DATE <=SYSDATE+1
AND T1.STMT_DATE > ADD_MONTHS(SYSDATE,-12)
语句特征
1.可以看语句涉及两张表:XXX_STMT_X(别名分别是为T1、T3),XXX_PTLOG(别名为T2)
2.两个表在查询条件中都涉及一个时间字段的过滤条件(T1、T3的STMT_DATE字段,T2的CREATE_DATE字段)
3.T1表分别与T2和T3存在等值关联;
接下来看SQL语句的执行情况统计:
Stat Name | Statement Total | Per Execution | % Snap Total |
Elapsed Time (ms) | 1,006,352,249 | 95.18 | |
CPU Time (ms) | 1,002,222,495 | 96.45 | |
Executions | 0 | ||
Buffer Gets | 26,706,214,212 | 71.81 | |
Disk Reads | 118,074 | 0.13 | |
Parse Calls | 0 | 0.00 | |
Rows | 0 | ||
User I/O Wait Time (ms) | 626,231 | ||
Cluster Wait Time (ms) | 363 | ||
Application Wait Time (ms) | 0 | ||
Concurrency Wait Time (ms) | 16 | ||
Invalidations | 0 | ||
Version Count | 36 | ||
Sharable Mem(KB) | 4,650 |
可以看到SQL的CPU时间总计超过100万秒,逻辑读达到了26G*8K即将近200个T!
这样看来,大部分执行时间都在CPU上,而非等到上,可以确定执行计划存在问题的!再具体看看执行计划:
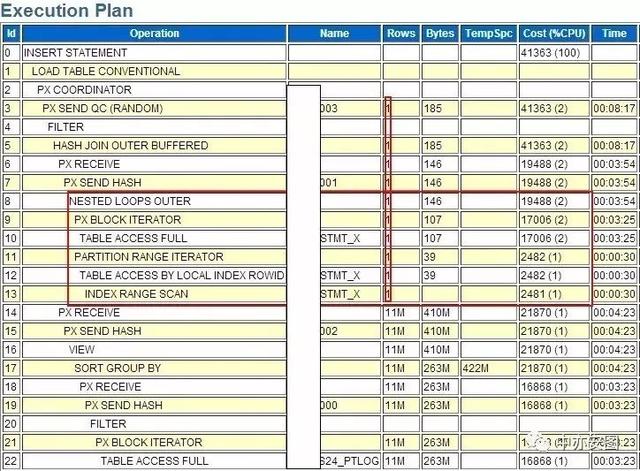
看上去,问题就简单了,对表XXX_STMT_X(T1)在过滤后评估行数为1,因此这里使用了nested loop的方式与T3关联,时间与逻辑读主要就花费在这里了;
以我的经验来看,如果这里XXX_STMT_X表与自己关联使用hash join的方式,再与表XXX_PTLOG表进行hash join;整个执行过程就不会太长;
我们对XXX_STMT_X表进行查询后得知,表XXX_STMT_X有1900+W行记录,应用过滤条件后数据大概也有一半数据量900+万记录,怎么到这里优化器评估这里的记录条数为1了呢?看起来,问题好像也没有什么特别的,就是统计信息不正确导致的执行计划问题嘛,也许收集一下统计信息就好了.你觉得呢?
统计信息的问题?
“我们之前还专门对表XXX_STMT_X做了统计信息收集,是不是统计信息收集的办法不对啊?”—客户继续说道;
我现场核查了统计信息的收集时间,以及统计信息显示出的信息,确实是没问题的,那么,会不会是过滤条件的特殊性导致的呢?这个可能需要小小的验证一下才行:
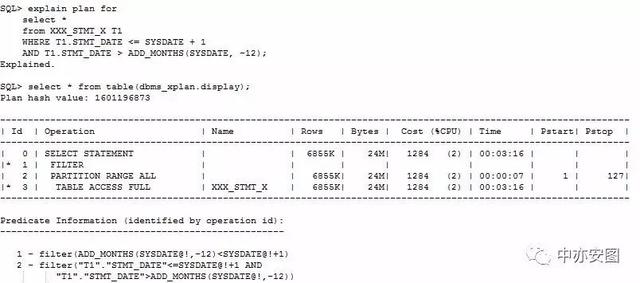
可以看到统计信息收集是没有问题的,单独做一个查询,优化器对表XXX_STMT_X的估算值还是挺准的; 可是怎么到了客户的批量语句里就出错了呢?是因为语句更多的连接关系?还是真的像客户所说的建了索引以后导致的?一切不得而知!如果是你,你接下来会如何分析这个问题呢?不如停下来思考思考.
.
找到错误评估的根源
这样的情况,我其实也没有遇见过,也没有可以直接借鉴的经验,不过作为老司机的一线DBA,我处理起来还是游刃有余的;要知道其生成执行计划时不准的原因,我们不妨做个10053看一看:
oradebug setmypid
oradebug event 10053 trace namecontext forever,level 1;
然后执行批量语句...
查看trace中对于表XXX_STMT_X的估算:
Accesspath analysis for XXX_STMT_X
***************************************
SINGLE TABLE ACCESS PATH --估算单表拜访路径
Single Table CardinalityEstimation for XXX_STMT_X[T1]
** Performing dynamicsampling initial checks. ** --启动了动态采样检查
Column (#107):
NewDensity:0.000557,OldDensity:0.000000 BktCnt:5387, PopBktCnt:5387, PopValCnt:126, NDV:126
Column (#107): STMT_DATE(
AvgLen: 8 NDV: 126Nulls: 0 Density: 0.000557 Min: 2456779 Max: 2457734
Histogram: Freq #Bkts: 126 UncompBkts: 5387 EndPtVals: 126
** Dynamic sampling initialchecks returning TRUE (level = 5).
--动态才有检查完成,级别为5
** Generated dynamicsampling query: --生成动态采样SQL
query text :
………………
** Executed dynamic sampling query:
level : 5
sample pct. : 0.015328—采样比0.015328
total partitions : 128 –-分区表分区总数128,实际分区数是127
partitions forsampling : 128
partitions actuallysampled from : 32 --真正采样的分区个数为32个
actual sample size : 0 --采集到的行数为0
filtered sample card. : 0 --满足过滤条件的为0
orig. card. : 19677057
block cnt. table stat. : 889706
block cnt. for sampling: 835048
partition subset block cnt. : 208762
max. sample block cnt. : 64
sample block cnt. : 32
min. sel. est. : 0.46621496
** Using single table dynamic sel. est. :0.00000000
Table: MDM_STMT_X Alias: T1
Card:Original: 19677057.000000 Rounded:1 Computed: 0.00 Non Adjusted: 0.00
--动态采样估算的返回行是0行
这里的问题就来了:明明这里XXX_STMT_X表中的数据有几百万上千万条记录,为什么采样后评估的记录数是0呢?
动态采样的算法过于internal,我们没法轻易拿到其各个细节的算法,不过,我们可以从MOS找到相关的bug类似如下:
Bug17760686 Bad Cardinality estimation with dynamic sampling
Affects:
Product (Component) | Oracle Server (Rdbms) |
Range of versions believed to be affected | Versions BELOW 12.2 |
Versions confirmed as being affected | |
Platforms affected | Generic (all / most platforms affected) |
11.2.0.4
11.2.0.3
11.2.0.2
Fixed:
The fix for 17760686 is first included in |
12.1.0.2 (Server Patch Set)
Description
A dynamic sampling may return a little or zero cardinalityestimate for a query involving a partitioned table stored on anASSM tablespace.
--当查询涉及到分区表时,动态采样可能会估算出很小甚至是0的结果集;
Workaround
Raise the level of dynamic sampling.
这个bug看起来很像,我们的XXX_STMT_X表同样也是分区表,但是并没有更多信息来确认我们的CASE就与这个bug有关;
在客户现场,我们应该怎么调整呢?照着这里的workaround的调整动态采样的级别吗?然而,当考虑这个workaround的时候,我才发现,我已经掉入了一个分析的陷阱,也许我们换个角度会更明朗,你发现了吗?
.
跳出分析的陷阱
当我们阅读10053的trace文件发现了动态采样出来的评估行数为0时,我们便一股脑进入到这个问题的分析/查找过程中;
然而,在这个过程中却着实忽略了一个重要的问题:表XXX_STMT_X上明明存在统计信息,为什么要使用动态采样呢,如果我们避免动态采样,是不是整个问题其实也就迎刃而解了呢?
要验证这个问题,我们简单的加个hint再看执行计划即可:
SELECT /*+dynamic_sampling(t1 0) dynamic_sampling(t3 0) */T1.BANK ,
…..
WHERE T1.STMT_DATE <= SYSDATE+ 1
AND T1.STMT_DATE > ADD_MONTHS(SYSDATE, -12) ;
查看对应的执行计划:
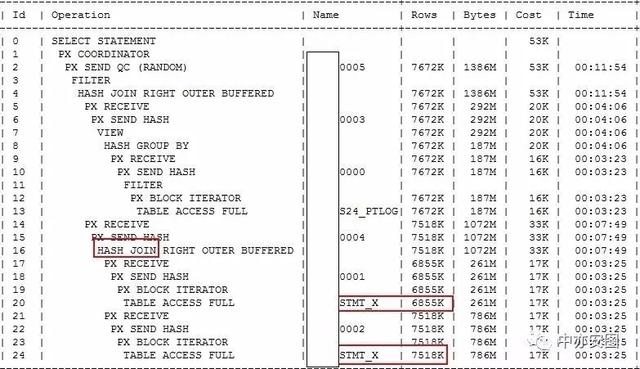
对表XXX_STMT_X的预估返回行都在700+W左右,和半年的数据量800+W在一个数据级.
并且由于预估返回行较多,所有优化器选择了HASH JOIN,而不是之前的NESTED LOOP.
由于在会话级加了16个并行,实测10min内可以执行完成;
没错,就是动态采样的问题,有统计信息而再去做动态采样,问题出在了哪里呢?
通常,我们会认为是数据库中参数设置的问题,然而我们可以在10053的trace文件中看到,系统中的非默认参数只包含下面几个:
***************************************
PARAMETERS USED BYTHE OPTIMIZER
********************************
*************************************
PARAMETERS WITH ALTERED VALUES
******************************
CompilationEnvironment Dump
parallel_query_forced_dop = 16
_pga_max_size = 1678540 KB
parallel_query_mode = forced
parallel_query_default_dop = 64
parallel_force_local = true
total_processor_group_count = 2
Bug Fix ControlEnvironment
*************************************
PARAMETERS WITH DEFAULT VALUES
******************************
可以看到,并没有特殊参数可以直接导致动态采样;那么,这里动态采样到底是从何而来呢?
找到问题的根本原因
当问题再次来到了经验范围之外时,MOS经常能给我们进一步拓宽思路,我们使用关键字dynamic sampling搜索,能找到不少相关文章,稍微浏览一番便能找到自己想要的东西;总结的文档有如下:
Different Level for DynamicStatistics (Dynamic Sampling) used than the Level Specified (文档 ID 1102413.1)
High Waits for 'cursor: pin S waiton X' due to Dynamic Sampling Against Parallel Queries (文档 ID 2006145.1)
Bug 17760686 - Bad Cardinalityestimation with dynamic sampling (文档 ID 17760686.8)
其中,文档2006145.1有如下论述:
Changes
The change in dynamic statistics is a result of anenhancement introduced in 11.2.
--11.2之后,Oracle对动态采样进行了增强.
In previous versions the default value lead to certain situationswhere the result from using dynamic statistics resulted in bad plans, forexample, when the tables referenced in the query are
very large.
With this enhancement the optimizer itself changes the dynamic value undercertain conditions such as with large tables and parallelism. Thelevel is automatically adjusted based on the size of the tables in the query.This is done only for queries that will run in parallel which is typical forData Warehouses and large databases.
--增强的功能是:在某些条件下,比如大表,开启并行和复杂谓词条件,优化器会自动启动动态采样,并且自行定义动态采样的级别.
The automatic setting of the Dynamic Statistic level is designed such thatoverhead from using Dynamic Statistics is kept to a very minimum yet it willimprove its effectiveness.
While the fix for this unpublished enhancement request bug7452863 ER: USE DYNAMIC SAMPLING FOR KEY CHOICES WHEN ROWESTIMATES ARE DUBIOUS, allows the auto-adjustment of the dynamicstatistic level for some queries, the tracing in 10053 may not correctlyreflect the adjustment made, and you may see a message of the sort:
--此特性是Oracle未公开的增强特性,相关FIX号是7452863
很显然,从我们的执行计划中可以很清晰的看到SQL启用了并行功能,而在11.2之后oracle提供的增强特性中,对于并行/大表的复杂条件,即使表上存在统计信息,它也会开启动态采样的功能,试图来更精准的评估返回结果集的记录数;然而,这里很不幸,遇上了动态采样本身的缺陷,导致动态采样后评估的行数反而大大偏离了实际情况,导致SQL语句执行时间超长;
对于该增强特性,MOS也提供了相应的办理方案:
Solution
1. Use workaround of turning off the following “_fix_control”. To do this, login assysdba and run the following:
alter system set “_fix_control”=’7452863:OFF';
--使用_fix_control参数关闭此特性
This turns off the automatic decisions about parallelism anddynamic sampling level.
2. Turn off parallelism from the table and indexes or set it to 1:
ALTER TABLE... NOPARALLEL;
ALTER TABLE ... PARALLEL 1;
ALTER INDEX... NOPARALLEL;
ALTER INDEX ... PARALLEL 1;
--或者不启动并行机制
到这里,考虑到批量语句中的涉及的表都非常大,还是需要使用并行查询来加快查询速度;同时,在没有进行全面测试的情况下,因为一个批量语句而修改系统整体参数显然也并不可取;
于是我们采取的最终办理方案是,在会话级别禁用这种增强特性:
alter session set “_fix_control”=’7452863:OFF';
最终,调整后,批量整体正常10分钟运行完成.
我们经历了什么
其实整个处理过程,写下来似乎有些平淡,但是在处理过程中还是经历了不少波折,特别是在偶尔的经验主义的作祟下,偏执于一点通常会限制我们的办理思路;那我们再回过头来看看我们到底经历了什么:
执行计划偏离了我们的预期,看起来像是统计信息不准
确认统计信息是相对准确的
通过10053跟踪发现,评估值不正确是因为优化器使用了动态采样而不是表上已有的统计信息来评估
对于大表XXX_STMT_X,动态采样的结果居然是0,显然动态采样过程存在问题
找到疑似动态采样结果不准的bug,但是无法精确匹配确认
跳出“动态采样不准”这一问题的陷阱,先思考为何要使用动态采样
再次核查相关文档,从中可以发现11.2版本后,oracle存在未公开的增强特性,对于大表/并行查询,即使相关表上存在统计信息,它依然会启动动态采样;
办理方案,通过参数关闭该增强特性,避免不必要的动态采样,也就避免了考虑动态采样不准确的问题
经验提示
对于这样CASE,我收获的经验是:
如果你以往的经验在问题中并不能帮助到你,这时就需要从原理上来分析该问题了;
在处理问题时,如果在一个问题点上长时间无法得到有效的方法,不妨跳出来,看看全局的方法;
从这个CASE可以看到,如果不了解SQL运行的背景和ORACLE的相关特性,而盲目的加索引、收集统计信息乃至加并行,并不能加快SQL的执行速度,甚至反而会让执行速度变慢(这里加并行后的执行效果反而不如加并行前);不知道这个CASE是否能给你带来这样的启发.
另,针对本CASE中动态采样不准的问题,在办理客户的问题后,我进一步进行研究验证,可以认为在动态采样过程中,是由于采样比例/采样语句中错误的hint及多种原因共同造成的,这里篇幅限制,不再进一步阐述,有兴趣的同学可以自行模拟出类似的CASE进行探索研究.
维易PHP培训学院每天发布《中亦科技黄远邦;颠覆传统调优方法的案例分享》等实战技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培养人才。
转载请注明本页网址:
http://www.vephp.com/jiaocheng/7861.html
同类教程排行
- Mysql实例mysql报错:Deadl
- MYSQL数据库mysql导入sql文件
- MYSQL的UTF8MB4编码排序要用u
- MYSQL教程mysql自定义split
- 如何打造MySQL高可用平台
- MYSQL创建表出错Tablespace
- Mysql必读MySQL中CLIENT_
- MYSQL数据库mysql常用字典表(完
- Mysql应用MySql的Communi
- Mysql入门解决MySQL Sendi
- Mysql必读关于skip_name_r
- MYSQL数据库MySQL实现两张表数据
- MYSQL数据库mysql 查询表中平均
- Mysql实例使用dreamhost空间
- MYSQL教程mysql 跨表查询、更新
