MySQL架构优化实战系列2:主从复制同步与查询性能调优
《MySQL架构优化实战系列2:主从复制同步与查询性能调优》要点:
本文介绍了MySQL架构优化实战系列2:主从复制同步与查询性能调优,希望对您有用。如果有疑问,可以联系我们。
1、主从复制同步部署
1、观点
主从复制:2台以上mysql服务器, 做负载均衡, 主服务器负责增编削 , 从服务器负责查询
同步原理:mysql开启bin-log日志,主服务器所有的增编削操作会记录到bin-log日志;然后主服务器把bin-log日志发送 给 从服务器 , 从服务器重放bin-log日志 确保数据同步
2、开启bin-log日记
设置装备摆设 my.cnf 文件 并重启 mysql
[root@localhost etc]# vim /etc/my.cnf
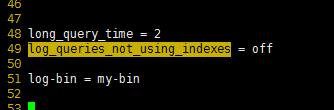
[root@localhost etc]# service mysql restart
开启之后 mysql-bin对应的文件 已经呈现
[root@localhost var]# cd /usr/local/mysql/var && ll
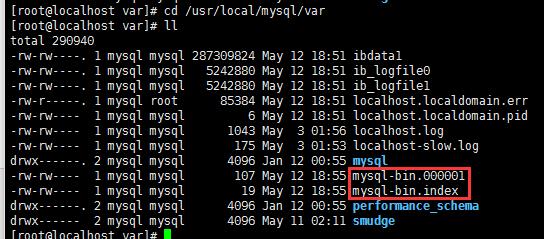
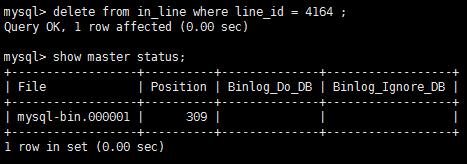
通过 show master status 命令查看 最新一个binlog日志 及开端行数
mysql> show master status;
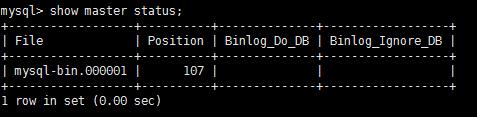
查看binlog日志内容 可见 最新一行日志在地位107
$ /usr/local/mysql/bin/mysqlbinlog /usr/local/mysql/var/mysql-bin.000001
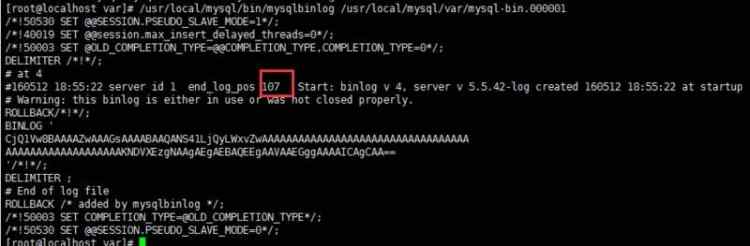
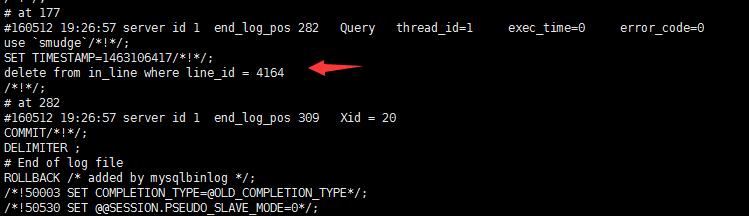
测试删除数据 可见 binlog文件新增日记内容
3、bin-log日志相关敕令
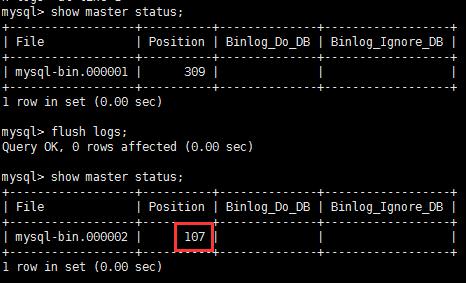
flush logs
新建一个binlog日志,增编削日志在新文件中插入,新的日志end-log-positon 是107行,107行记录了mysql内部日志.
reset master
清空所有bin-log日志 只保存 mysql-bin.000001 文件
mysqlbinlog
查看bin-log日记/usr/local/mysql/bin/mysqlbinlog/usr/local/mysql/var/mysql-bin.00001
show binlog events 查看binlog记录变乱
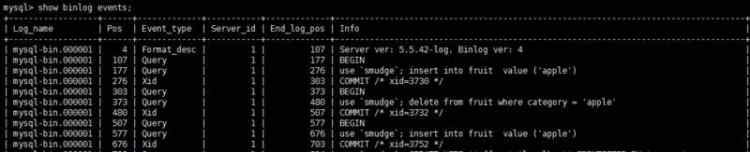
mysqlbinlog mysql -uroot -psmudge smudge_database
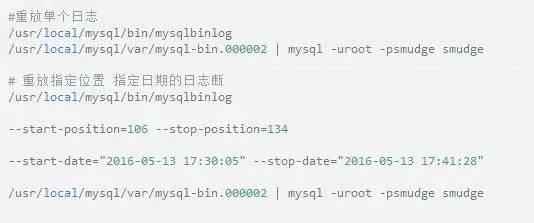
重放bin-log日志、恢复数据:其实就是再把日志中的sql语句执行一边罢了.(注意:select 语句 和delete语句 不可以放在一起重放 因为你最后还是得不到数据)
恢复原理便是:执行之前的insert语句,或者之前的update语句
如果你的单纯的delete物理删除,别想规复了,因为再次执行的还是delete语句
4、create 创立用户 + grant用户授权
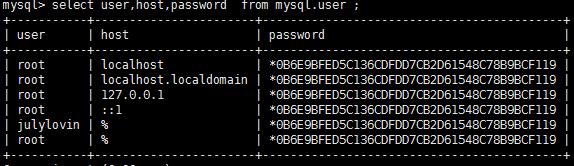
主服务器查看用户暗码
mysql> select host,user,password from mysql.user;
添加主服务器用户暗码
CREATE USER 'kang'@'192.168.206.132' IDENTIFIED BY 'smudge';
创建用户kang 可以在ip为192.168.206.132主机上拜访数据库

给用户kang受权所有的库的权限

5、主服务器设置装备摆设
主服务器ip:192.168.206.128
设置装备摆设主服务器my.cnf 文件
vim /etc/my.cnf
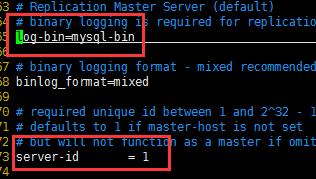
设置装备摆设之后刷新binlog文件
flush logs with read lock 确保获得一致性快照,等待主从binlog日志同步完毕到达数据一致
又或使用mysqldump备份sql 文件
将主服务器一致都是sql文件备份,通报到从服务器
mysqldump -uroot -psmudge smudge -l -F > '/home/smudge.sql'
-l 是指锁表 避免新数据插入
-F 是刷新 生成一个新的binlog日记
(假如你数据库中有merge表 容易会提示Unable to open underlying table which is differently defined or ofnon-MyISAM type ordoesn't exist when using LOCK TABLES )

使用scp隧道传输敕令 传递文件
scp /home/smudge.sql 192.168.206.132:/home

6、从服务器设置装备摆设
恢复一部门主服务器备份的数据
新建smudge库
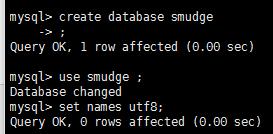
mysql导入sql文件
[root@localhost~]# mysql -uroot -psmudge smudge < /home/smudge.sql
设置装备摆设从服务器my.cnf文件
vim /etc/my.cnf
其中用户名和暗码就是上述我们在主服务器添加的信息
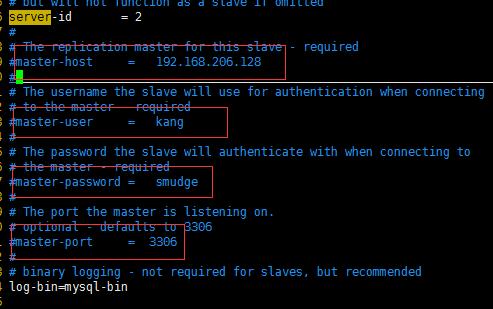
(如果你的mysql版本5.1(mysql>status查看)之前的,配置这4项,启动之后就不必使用change master 敕令 进行主动同步)
保留并重启mysql
查看主服务器master binlog文
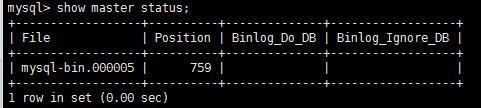
启动slave过程,开启主从同步
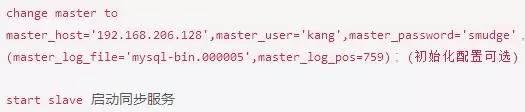
因为我的mysql版本是5.7的, 所以我使用change master敕令
show slave status 查看从服务器状况
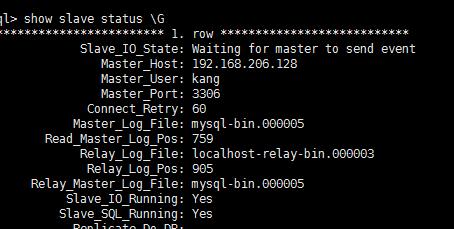
注解同步功能已经开启
7、从服务器常用敕令
start slave 启动复制线程
stop slave 结束复制线程
show master logs 查看主数据库日记
change master to master_host ,master_user 静态切换主数据库
show processlist 查看运行过程 (主动服务器都适用)
8、常见差错排错
show slave status 反省主动状态
20 数值为NO
21 数值为
注解同步出现了故障,可能是slave服务器执行了写操作或者从服务器重启有事务回滚操作.
办理
从服务器: stop slave 封闭复制线程
主服务器:show master status 查看最新二进制文件和地位偏移量
从服务器执行:change master to master_host ...
master_log_file='mysql-bin.000005',master_log_pos=759 敕令
二、查询机能优化
1、查询执行根基知识
mysql执行查询进程
① 客户端将查询发送到服务器
② 服务器检查查询缓存 如果找到了就从缓存返回结果 不然进行下一步
③ 服务器解析,预处置和优化查询,生成执行计划
④ 执行引擎挪用存储引擎api执行查询
⑤ 服务器将成果发送回客户端
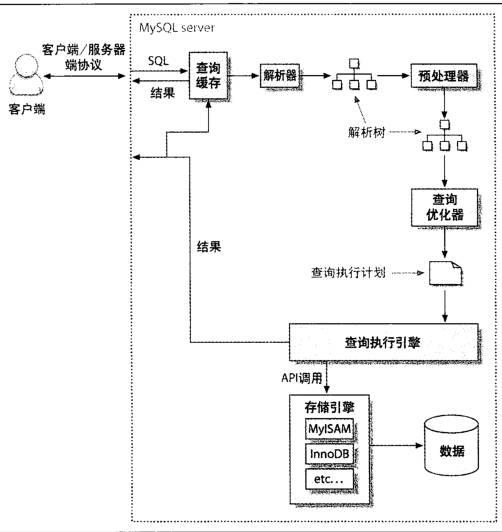
mysql客户端/服务器协定
该协议是半双工通信,可以发送或接收数据,但是不克不及同时发送和接收决定了mysql的沟通简单又快捷;
缺点:无法进行流程控制,一旦一方发送消息,另一方在发送回复之前必需提取完整的消息,就像抛球游戏,任意时间,只有某一方有球,而且有球在手上,否则就不能把球抛出去(发送消息)
mysql客户端发送/服务器相应
可以设定max_packet_size这个参数控制客户端发送的数据包(一旦发送数据包,唯一做的便是等待结果)
服务器发送的响应由多个数据包组成, 客户端必须完整接收结果,即使只需要几行数据,也得等到全部接收 然后丢掉,或者强制断开连接.(这两个办法好挫,所以我们使用limit子句呀!!)
也可以理解,客户端从服务器 "拉" 数据 ,实际是服务器产生数据 "推"到客户端, 客户端不能说不要 是必需全部装着!
常用的Mysql类库 其实是从客户端提取数据 缓存到array(内存)中,然后进行 foreach 处置.
但是对于庞大的结果集装载在内存中必要很长时间,如果不缓存,使用较少的内存并且可以尽快工作,但是应用程序和类库交互时候,服务器端的锁和资源都是被锁定的.
查询状况
每个mysql连接都是mysql服务器的一个线程 任意一个给定的时间都有一个状态来标识正在产生的事情.
使用 show full processlist 敕令查看
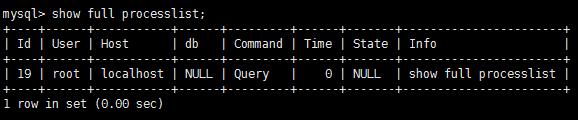
mysql中一共有12个状态:休眠、查询、锁定、阐发和统计、拷贝到磁盘上的临时表、排序结果、发送数据,通过这些状态 知道 "球在谁手上".
查询缓存
解析一个查询,如果开启了缓存,mysql会反省查询缓存,发现缓存匹配,返回缓存之前,反省查询的权限.
2、优化数据拜访
查询性能低下最基本的原因是拜访了太多的数据,分析两方面:
① 查明应用程序是否获取超过需要的数据 通常意味着拜访了过多的行或列
② 查明mysql服务器是否分析了超过必要的行
向服务器哀求了不需要的数据
一般哀求不需要的数据,再丢掉他们,造成服务器额外的负担,增加网络开销,消耗了内存和cpu.
典型的差错:
① 提取超过必要的行 => 添加 limit 10 控制获取行数
② 多表联接提取所有列 => select fruit.* from fruit left join fruit_juice where
.....
③ 提取所有的列 => select id,name... from fruit ... (有时提取超过必要的数据便于复用)
mysql检查了太多半据
简单的开销指标:执行时间、反省的行数、返回的行数.
以上三个指标写入了慢查询日志 可以使用 mysqlsla工具进行日志阐发:
① 执行时间:执行时间只是参考 弗成一概而论 因为执行时间 和服务器当时负载有关
② 检查和返回的行:抱负情况下返回的行和检查的行一样,但是显示基本不可能 比如联接查询
③ 检查的行和拜访类型: 使用explain sq语句,观察typ列

typ列:(拜访速度依次递增)
① 全表扫描(full table scan)
② 索引扫描(index scan)
③ 规模扫描(range scan)
④ 独一索引查找(unique index lookup)
⑤ 常量(constant)
可见type列为index即sql语句,基于索引扫描:
rows列为12731,即扫描了12731行 extra列为using index,即使用索引过滤不必要的行
mysql会在3种环境下使用where子句,从最好到最坏依次是:
① 对索引查找应用where子句来消除不匹配的行 这产生在存储层
② 使用覆盖索引(extra 列 "using index") 避免拜访行 从索引取得数据过滤不匹配的行 这发生在服务层不需要从表中读取行
③ 从表中检索出数据 过滤不婚配的行(extra:using where)
如果发现拜访数据行数很大,尝试以下措施:
① 使用笼罩索引 ,存储了数据 存储引擎不会读取完整的行
② 变动架构使用汇总表
③ 重写繁杂的查询 让mysql优化器优化执行它
3、重构查询的方式
优化有问题的查询,其实也可以找到替代计划,提供更高的效率.
繁杂查询和多个查询
mysql一般服务器可以每秒50000个查询,惯例情况下,使用尽可能少的查询 有时候分解查询得到更高的效率.
缩短查询
分治法,查询本色上不变,每次执行一小部分,以减少受影响的行数.比如清理陈旧的数据,每次清理1000条:
delete from message where create < date_sub(now,inteval 3 month)
limit 1000
防止长光阴锁住很多行的数据.
分化联接
把一个多表联接分解成多个单个查询 然后在应用法式实现联接操作
第一眼看上去比拟浪费,因为增加了查询数量,但是有重大的性能优势:
① 缓存效率高,应用法式直接缓存了表 类似第一个查询直接跳过
② 对付myisam表来说 每个表一个查询有效利用表锁 查询锁住表的时间缩短
③ 应用程端进行联接更便利扩展数据库
④ 使用in 避免联表查询id排序的消耗
⑤ 减少多余行的拜访 , 意味着每行数据只拜访一次 避免联接查询的非正则化的架构带来的反复拜访同一行的弊端
分解联策应用场景:
① 可以缓存早期查询的年夜量的数据
② 使用了多个myisam表(mysiam表锁 并发时候 一条sql锁住多个表 所以要分化)
③ 数据分布在分歧的服务器上
④ 对于年夜表使用in 替换联接
④ 一个联接引用了同一个表许多次
提取随机行

分组查询

外键
只有Innodb引擎支持外键,myisam可以添加外键然则没有效果.
主表添加主键id,从表添加外键id援用主表的id.
表student
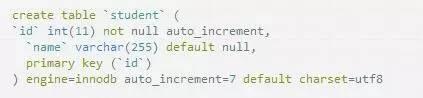
表student_extend
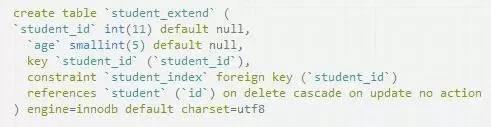
为student_extend添加外键,外键指向student表中的id列,在delete时触发外键.
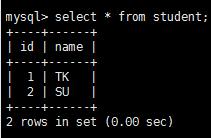
表student数据
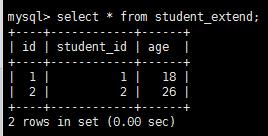
表student_extend数据
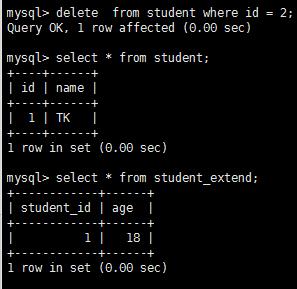
删除了表student一条数据,则外键表就会触发外键,删除了对应数据:
delete from student where id = 2;
优化结合查询

优化max min
此中 name 没有索引

对一个表同时进行select以及update
维易PHP培训学院每天发布《MySQL架构优化实战系列2:主从复制同步与查询性能调优》等实战技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培养人才。
转载请注明本页网址:
http://www.vephp.com/jiaocheng/7830.html
同类教程排行
- Mysql实例mysql报错:Deadl
- MYSQL数据库mysql导入sql文件
- MYSQL的UTF8MB4编码排序要用u
- MYSQL教程mysql自定义split
- 如何打造MySQL高可用平台
- Mysql必读MySQL中CLIENT_
- MYSQL创建表出错Tablespace
- MYSQL数据库mysql常用字典表(完
- Mysql应用MySql的Communi
- Mysql入门解决MySQL Sendi
- Mysql必读关于skip_name_r
- MYSQL数据库MySQL实现两张表数据
- Mysql实例使用dreamhost空间
- MYSQL数据库mysql 查询表中平均
- MYSQL教程mysql 跨表查询、更新
