一个简单的开源PHP爬虫框架——Phpfetcher
《一个简单的开源PHP爬虫框架——Phpfetcher》要点:
本文介绍了一个简单的开源PHP爬虫框架——Phpfetcher,希望对您有用。如果有疑问,可以联系我们。
我就是在头条号凑个热闹,欢迎大家到http://blog.reetsee.com/archives/366查看原文.
转载请注明:吹水小镇 | reetsee.com
原文链接地址:http://blog.reetsee.com/archives/366
—————————————————
好久不见了!我终于又写一篇日志了,本来有很多流水帐想发但是感觉没营养,就作罢了.
今天我主要分享一个简单的PHP爬虫框架,名字叫:Phpfetcher
项目的地址是:https://github.com/fanfank/phpfetcher
这个框架的作者是:reetsee.xu,即吹水.
把整个项目下载下来后,在Linux下的终端直接执行demo文件夹下的single_page.php即可看到效果.不过在执行demo文件前,先设置一下你的终端编码为UTF-8以免显示乱码:
export.UTF-8
—————————————————
0 背景
背景是这样的目前吹水新闻(http://news.reetsee.com)下的内容全部由Python的爬虫抓取,使用的框架是Python的Scrapy,而吹水新闻目前是运行在BAE(百度应用引擎)下的,每个月还需要交钱.目前我的想法是把吹水新闻完全迁移到目前这台阿里云主机上,并且原本的新闻我每天都手动执行一次脚本来抓取再更新到网站,等迁移到这里后就能直接使用Crontab定时脚本自动更新新闻了!
最近工作都在用PHP,开发网站的新页面要PHP,直接读写数据库也能用PHP,那么就直接用PHP重构新闻网站好了.
准备开干的时候却发现没找到一个好的PHP爬虫框架(可能是我没仔细找),于是就打算自己写一个,因此就有了这个Phpfetcher.
名字起得略好……但是代码写得略搓……不管怎么样,目前基本可以用,而且应该能满足不少简单的需求,下面就是使用示例.
—————————————————
1 基本概念
在Phpfetcher中有四个主要的对象,依次是:Dom,Page,Crawler,Manager.
Dom对象用来解析html,能够访问html里的dom;
Page对象对应到一个具体的html页面,能够取得整个网页的内容,Page对象中有一个Dom对象的成员;
Crawler对象可以理解为就是爬虫对象,用来设置要爬取页面的规则;
Manager对象原本是用来管理Crawler对象的,以后或许能用来在多进程环境下使用,但目前没有实现,所以暂时没有用;
大致概念就是这样了,实际使用主要是操作Crawler对象.在Phpfetcher中,你可以实现自己的Dom,Page和Crawler,只要符合基类的要求即可.
要说明的是Phpfetcher的默认Page对象中的Dom对象使用的是simple_html_dom,没有使用PHP提供的DOMDocument类,因为我发现DOMDocument对HTML格式的内容兼容性比较差,有时网页中混入其它内容时可能解析不出dom.
下面这张是图是Phpfetcher的目录结构:

你可以根据自己的需要定制想要的Crawler,Page,Dom类,默认情况下我提供了Crawler的默认类是Phpfetcher_Crawler_Default,Page的默认类是Phpfetcher_Page_Default,Dom的默认类是Phpfetcher_Dom_SimpleHtmlDom.类名和它们所在的路径有对应关系.要注意的是,在使用默认的Page对象时需要PHP的curl库,使用默认的Crawler对象时需要使用PHP的mb_string库,没有的需要装一下.
为了便于理解,我画了几张图,第一张是Phpfetcher的三个主要对象之间的关系:

图里表示的是Crawler里面有Page的对象,Page里面有Dom的对象.
在使用Phpfetcher时,最重要的是完成下图中两个绿色矩形框要求的事情:

即你要写一个类继承Phpfetcher提供的Crawler类,然后在你自己的类中实现一个名为handlePage($page)的函数.其中$page参数是一个Phpfetcher的Page类对象.
最后这里给出一个基本的流程图:
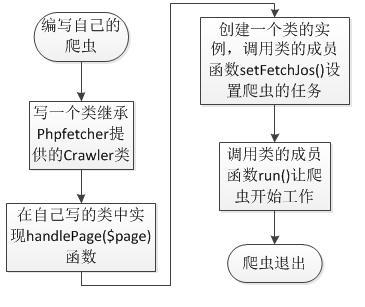 上面说的东西有点虚,那还是直接看实例吧!
上面说的东西有点虚,那还是直接看实例吧!
—————————————————
2 简单例子
****** 实例1:single_page.php ******
例如我们要抓取这个网站的内容:http://news.qq.com/a/20140927/026557.htm
里面有很多超链接,有标题,有新闻详细内容,或者其它我们关心的内容.
先看一下下面的例子:
<?php
require_once('phpfetcher.php');
class mycrawler extends Phpfetcher_Crawler_Default {
public function handlePage($page) {
//打印处当前页面的title
$res = $page->sel('//title');
for ($i = 0; $i < count($res); ++$i) {
echo $res[$i]->plaintext;
echo "\n";
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
//任务的名字随便起,这里把名字叫qqnews
//the key is the name of a job, here names it qqnews
'qqnews' => array(
'start_page' => 'http://news.qq.com/a/20140927/026557.htm', //起始网页
'link_rules' => array(
/*
* 所有在这里列出的正则规则,只要能匹配到超链接,那么那条爬虫就会爬到那条超链接
* Regex rules are listed here, the crawler will follow any hyperlinks once the regex matches
*/
),
//爬虫从开始页面算起,最多爬取的深度,设置为1表示只爬取起始页面
//Crawler's max following depth, 1 stands for only crawl the start page
'max_depth' => 1,
) ,
);
//$crawler->setFetchJobs($arrJobs)->run(); 这一行的效果和下面两行的效果一样
$crawler->setFetchJobs($arrJobs);
$crawler->run();
将这个脚本和“phpfetcher.php”以及“Phpfetcher”文件夹放在同一个目录下(或者将“phpfetcher.php”和“Phpfetcher”放到你的PHP环境默认include的查找路径),执行这个脚本,得到的输出如下:
[root@reetsee demo]# php single_page.php
王思聪回应遭警方调查:带弓箭不犯法 我是绿箭侠_新闻_腾讯网
查看一下我们抓取的网页源代码,可以发现是下面这几行中的title标签内容提取出来了:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312"></meta>
<meta charset="gb2312"></meta>
<title>
王思聪回应遭警方调查:带弓箭不犯法 我是绿箭侠_新闻_腾讯网
</title>
上面就是一个最简单的例子.
****** 实例2:multi_page.php ******
接下来就是另外一个简单的例子,例如说腾讯新闻的主页,上面有各种新闻,我们这次的目标是把腾讯新闻主页(http://news.qq.com)显示的部分新闻标题抓下来,直接先上例程:
<?php
//下面两行使得这个项目被下载下来后本文件能直接运行
$demo_include_path = dirname(__FILE__) . '/../';
set_include_path(get_include_path() . PATH_SEPARATOR . $demo_include_path);
require_once('phpfetcher.php');
class mycrawler extends Phpfetcher_Crawler_Default {
public function handlePage($page) {
//打印处当前页面的第1个h1标题内荣(下标从0开始)
$strFirstH1 = trim($page->sel('//h1', 0)->plaintext);
if (!empty($strFirstH1)) {
echo $page->sel('//h1', 0)->plaintext;
echo "\n";
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
//任务的名字随便起,这里把名字叫qqnews
//the key is the name of a job, here names it qqnews
'qqnews' => array(
'start_page' => 'http://news.qq.com', //起始网页
'link_rules' => array(
/*
* 所有在这里列出的正则规则,只要能匹配到超链接,那么那条爬虫就会爬到那条超链接
* Regex rules are listed here, the crawler will follow any hyperlinks once the regex matches
*/
'#news\.qq\.com/a/\d+/\d+\.htm$#',
),
//爬虫从开始页面算起,最多爬取的深度,设置为2表示爬取深度为1
//Crawler's max following depth, 1 stands for only crawl the start page
'max_depth' => 2,
) ,
);
$crawler->setFetchJobs($arrJobs)->run(); //这一行的效果和下面两行的效果一样
//$crawler->setFetchJobs($arrJobs);
//$crawler->run();
相比于第1个例子,变化的地方有几个:首先这次我们增加了一条爬虫跟踪的规则“#news\.qq\.com/a/\d+/\d+\.htm$#”(注:PHP使用pcre正则表达式,可以到PHP关于正则表达式的页面看一下),这是一个正则表达式,例如这种超链接“news.qq.com/a/12345678/00234.htm”那么爬虫就会跟踪;然后是我们把爬虫的最大跟踪深度设置为2,这样爬虫会跟踪1次起始页面上符合要求的超级链接;最后是我把原本的Dom选择从“//title”改为了“//h1”,意思就是抓取h1标签的内容而不是像之前那样抓取title标签,想知道这种Dom选择器的选择规则,需要了解一下xpath.
运行这个文件,能够看到大致效果如下:

这样第二个例子就结束了.
暂时我就介绍这两个例子吧,Phpfetcher的源代码在这里:https://github.com/fanfank/phpfetcher
把代码下载下来后,demo内的东西就可以直接运行了(当然你需要一个有curl和mb_string扩展的php,可以使用“php -m”命令来看一下你的PHP有没有装这两个扩展).
—————————————————
3 后话
实际上这个phpfetcher目前还有很多问题,性能应该是比较差的,不过毕竟也是我写的第一个框架.
另外是关于phpfetcher我有很多东西还没有提到,例如Page对象的一些设置,Crawler对象的设置等,主要是目前太过懒不想写文档,也不知道有没有必要写.我感觉这个框架还是蛮简单的,里面主要的函数我都做了详细的注释,欢迎阅读批评指正给建议!
最后就是,如果你想写个爬虫,又想用PHP来写,不妨试一下phpfetcher.
转载请注明:吹水小镇 | reetsee.com
原文链接地址:http://blog.reetsee.com/archives/366
维易PHP培训学院每天发布《一个简单的开源PHP爬虫框架——Phpfetcher》等实战技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培养人才。
转载请注明本页网址:
http://www.vephp.com/jiaocheng/9363.html
同类教程排行
- 为什么我们要用Laravel、Yii这样
- 框架和编程语言市场份额和排名,PHP占到
- 盘点各种程序员最讨厌的事情,看看你中招了
- 3分钟快速入门php高性能框架Phalc
- 一款强大的纯PHP开发的爬虫(蜘蛛)框架
- 国产PHP框架之ThinkPHP各模块开
- PHP框架——ThinkPHP模块开发四
- 分享一款不错的PHP爬虫框架Beanbu
- 二维码高级在线生成器站点 PHP 源码
- Php框架之slim3.0应用小实例
- PHP框架——ThinkPHP各模块开发
- PHP 组件及框架推荐系列:PHP世界中
- yii2框架路由配置和url美化干货,学
- 基于php的爬虫程序推荐
- dedecms发手机短信的源码,做旅游网
