Terark 联合 MongoDB改进WiredTiger
《Terark 联合 MongoDB改进WiredTiger》要点:
本文介绍了Terark 联合 MongoDB改进WiredTiger,希望对您有用。如果有疑问,可以联系我们。
相关主题:非关系型数据库
欢迎参与《Terark 联合 MongoDB改进WiredTiger》讨论,分享您的想法,维易PHP学院为您提供专业教程。
2017-09-13 雷鹏 Terark实验室

1.
背景
WiredTiger 是 KeyValue 存储引擎,它最大的应用场景是作为 MongoDB 的默认存储引擎,同时 MongoDB 对 WiredTiger 性能改进的探索也从未停止,于是,TerarkDB 以卓越的性能和压缩率而获得了 MongoDB 的兴趣……
鉴于 TerarkDB 是 Terark 核心算法对 RocksDB 的适配,理论上相同的算法也可以用于 WiredTiger,我们经过一段时间的紧密开发,实现了第一个测试版本,期间 WiredTiger 的作者提供了大力的支持,在这里我们跟大家分享一下开发的经历与成果.
2.
WiredTiger 和 LSM
WiredTiger 本身支持 BTree 和 LSM ( Log-Structured Merge Trees ) 两种数据结构进行数据存储,用户通常可以根据自己的需求进行选择.
2.1. BTree
BTree 读性能优良.但是在写压力较大的情况下,性能会下降的较为严重:
BTree 的写放大很严重:很少量的写就会引起整页被重新写入磁盘,假定一个页包含 200 条记录,其中有 2 条被修改,当该页被换出时,就需要将整个页都写入磁盘/SSD,象这样 2 条数据修改导致 200 条数据被写入磁盘,其写放大就是 100 倍.
这在 SSD 上导致了更加严重的后果:因为 SSD 的寿命取决于写次数,频繁写入会大幅降低 SSD 的寿命.
2.2. Log-Structured Merge Trees
LSM 是一个针对写而进行了优化的数据结构,一个 LSM 在物理层面由多个子片段组成,其中最近被更新的那个片段存在于内存中,其余的以文件的方式存储在磁盘中,当内存片段达到阈值时会被持久化成文件,同时产生一个新的内存片段用于写操作.
这里,通过将所有的写操作以追加的方式写到内存中,就规避了 BTree 中出现的写一条数据往往需要先读磁盘,然后修改,然后再写回磁盘的弊端.只需要在达到阈值时一次性的 flush 即可.
当然,LSM 也有它自己的弊端,写的优化伴随着读性能的下降.简单追加写的方式意味着子片段之间可能会有数据的重叠,查询也就往往需要读取多个子片段才能返回有效的结果.LSM 通过后台线程对已有数据进行 compact 来解决(缓解)这个问题.
3.
WiredTiger 接口层
WiredTiger 提供了一套回调接口以方便用户按照自己的需求去定制底层的数据存取.例如,LSM 的每一个子文件,数据是按照 BTree 的方式进行存取的.熟悉 LevelDB / RocksDB 的同学可以通过回调实现一份以 Block Based 为组成文件的 LSM,和 原生的 BTree 比较一下性能.
WiredTiger 的回调接口如下:
static WT_DATA_SOURCE my_dsrc = {
alter,
create,
compact,
drop,
open_cursor, // *
rename,
salvage,
truncate,
range_truncate,
verify,
checkpoint,
terminate
};
error_check(conn->add_data_source(conn, "dsrc:", &my_dsrc, NULL));
回调里包含了创建、删除、重命名、停止等函数.这里需要注意标 * 的 open_cursor 回调,用户程序对 wt 的访问,是统一经由抽象的 cursor 来实现的.
WiredTiger 的内部也遍布了 cursor 的调用,所以要重载数据存储实现,cursor 相关的操作也不可避免:
WT_CURSOR::close
WT_CURSOR::next
WT_CURSOR::prev
WT_CURSOR::reset
WT_CURSOR::search
WT_CURSOR::search_near
WT_CURSOR::insert
WT_CURSOR::update
WT_CURSOR::remove
4.
将 Terark 算法集成进 WiredTiger
基于上面的理由,我们为 LSM 实现了一个 TerarkZipTable 数据源,把我们的可检索压缩算法嵌入到 WiredTiger 中.
4.1. LSM-Chunk
LSM-chunk (在WiredTiger语境里,LSM-file 以 chunk 来指代)或者是由内存数据转化而成,或者是由若干个 chunk 通过 compact 生成.无论哪种方式,遍历源数据都是必不可少的.为了实现高压缩率和可检索压缩,Terark-chunk 需要遍历源数据二次,对比原生的 LSM-chunk 只需要遍历一次.这里的差异,可以简单理解为Terark需要第一遍收集全局信息,为压缩做准备,第二遍执行压缩.
4.2. 重载粒度
需要强调的是,WiredTiger 的数据源含义较为宽泛,它可以是 LSM,也可以是组成 LSM 的子文件即 LSM-chunk.
我们这里重载的,是 LSM-chunk,涉及到 LSM 层面的 Merge , Checkpoint 是未受影响的.
4.3. 来自 WiredTiger 官方的协助
在整个修改过程中,WiredTiger 本身也有一些需要调整和修改的地方,为此 WiredTiger 在一个新分支上与我们进行协作:
1. 为了支持两次遍历,WiredTiger 为我们提供了一个额外的接口;
2. LSM-chunk 默认是以 BTree 方式实现的并在几处代码内写死了,新分支已经修复;
3. WiredTiger 内部是按照名称前缀来判断数据类型的,LSM-chunk 对应的前缀是 BTree 通用的 file:,不巧有几处也写死了,新分支已修复;
4. LSM-chunk 默认需要生成 Bloom Filter 文件以提高查找效率,而 Terark 并不需要该文件,新分支目前正在修改,但不影响我们的测试;
5. 为了保证 Transaction 相关操作不受影响,WiredTiger 内存驻留的 LSM-chunk 仍然以 BTree 方式存在,其他的 chunk 可以通过重载 data-source 来实现,新分支已改;
6. 经过我们的提议,WiredTiger 新增了一个 cursor 选项(unpositioned),该选项指示 CURSOR::search 不要保留 cursor 位置
1)之前 WiredTiger 的 CURSOR::search 在搜索成功时总会保留 cursor 的位置;
2)而维护 cursor 位置的搜索已由接口 CURSOR::search_near 提供完美支持;
3)对于 TerarkZipTable,保留 cursor 位置是一笔不小的开销
无 unpositioned 选项时,TerarkZipTable 通过投机方法来减小这种开销;
有 unpositioned 选项时,就可以完全避免这种不必要的开销.
4.4. TerarkDB 不需要 Bloom Filter
Bloom Filter 用来做否定测试,也就是说,如果 Bloom Filter 搜索 Key 失败,则该 Key 一定不存在,如果 Bloom Filter 搜索成功,该 Key 可能存在,也可能不存在.
Bloom Filter 的优点是占用空间很小(一般情况下平均每个 Key 1~2 字节),搜索速度又很快,当然缺点就是它只能确认 Key 不存在.
传统 SST 使用 Bloom Filter 来加速高层 Level 中 SST 的搜索.
高层(Level 值更小的 Level)的数据尺寸更小,并且都是新数据,访问更频繁,未命中的概率更高,而传统索引搜索速度较慢,内存占用高,所以,用 Bloom Filter 可以实现很好的加速效果,并且相对内存占用较低.
然而,Terark SST 用了 CO-Index,CO-Index 的压缩率和性能都非常高,和 Bloom Filter 相比,甚至在很多情况下空间和搜索性能同时占优,而且还是确定性的搜索(存在就是存在,不存在就是不存在),所以 Terark SST 就完全舍弃了 Bloom Filter.
4.5. 实现接口
WT_DATA_SOURCE
trk_create
trk_drop
trk_open_cursor
trk_pre_merge // *
这里的 trk_pre_merge 是 WiredTiger 官方提供的新的接口,用来供 Terark 实现两次遍历.
WT_CURSOR @ building
trk_builder_cursor_insert
trk_builder_cursor_close
trk_builder_cursor_reset
WT_CURSOR @ reading
trk_reader_cursor_next
trk_reader_cursor_prev
trk_reader_cursor_search
trk_reader_cursor_search_near
trk_reader_cursor_close
trk_reader_cursor_reset
上面的接口显示,每个 chunk 按功用可以划分为两个阶段:构建和查询.
构建阶段的 chunk 不需要提供 search 相关的功能,此时对应的回调可以设置为 NULL;同理,一旦 chunk 构建完毕,它就是 immutable 的,不需要考虑 insert 相关的操作.所以这里的 cursor 按照 chunk 的生命期拆分为两组.
需要留心的有以下几点:
初始化的 cursor 可以立即调用 next(),此时是从头开始正向遍历;
初始化的 cursor 可以立即调用 prev() ,此时是从尾开始反向遍历;
search()对应的是精确查找,search_near()对应的是类 lower_bound() 的查找;
5.
初步的集成测试结果
5.1. 测试环境
CPU: Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz x2 (共16核32线程)
内存: DDR4 1866 MHz(共192G)
SSD: INTEL 730 IOPS 89000
CentOS Linux release 7.3.1611 (Core)
5.2. 测试数据
测试程序使用的是我们自己开发的测试工具: terarkdb-tests
测试数据使用了 Wikipedia,原始数据约 103 GB
5.3. 测试准备
分别使用原生 wiredtiger-with-snappy 和 适配了 terark-as-data-source 的 引擎,灌入上文提到的数据,总大小102G . 数据的前3列合并作为 key, 剩余的字段作为 value.
原生 wiredtiger 生成的数据集大小是 62G,其中 bloom-filter 文件 0.1G,数据文件 62G .
适配 terark 生成的数据集大小是 23G,因为是可检索压缩,所以不需要 bloom-filter.
原生 WiredTiger 配置:
wiredtiger_open
(
db
=./
wiredtigerdb_lsm
,
conf
=
create
,
cache_size
=
137438953472
,
log
=(
enabled
,
recover
=
on
),
checkpoint
=(
log_size
=
64MB
,
wait
=
60
),
lsm_manager
=(
worker_thread_max
=
8
),
extensions
=[
libwiredtiger_snappy
.
so
])
session
->
create
(
uri
=
lsm
:
dbbench_wt
-
0
,
conf
=
key_format
=
S
,
value_format
=
S
,
checksum
=
off
,
internal_page_max
=
128K
,
leaf_page_max
=
16K
,
type
=
lsm
,
os_cache_dirty_max
=
16MB
,
lsm
=(
bloom_config
=(
leaf_page_max
=
8MB
),
bloom_bit_count
=
28
,
bloom_hash_count
=
19
,
bloom_oldest
=
true
,
chunk_max
=
40GB
,
chunk_size
=
100MB
,
merge_min
=
2
),
block_compressor
=
snappy
)
修改版配置:
wiredtiger_open
(
db
=./
wiredtigerdb_terark
,
conf
=
create
,
cache_size
=
34359738368
,
log
=(
enabled
,
recover
=
on
),
checkpoint
=(
log_size
=
64MB
,
wait
=
60
),
lsm_manager
=(
worker_thread_max
=
8
),
extensions
=[
libwiredtiger_snappy
.
so
])
session
->
create
(
uri
=
lsm
:
dbbench_wt
-
0
,
conf
=
key_format
=
S
,
value_format
=
S
,
checksum
=
off
,
internal_page_max
=
128K
,
leaf_page_max
=
16K
,
type
=
lsm
,
os_cache_dirty_max
=
16MB
,
lsm
=(
bloom_config
=(
leaf_page_max
=
8MB
),
bloom_bit_count
=
28
,
bloom_hash_count
=
19
,
bloom_oldest
=
true
,
chunk_max
=
20GB
,
chunk_size
=
500MB
,
merge_min
=
2
,
merge_custom
=(
prefix
=
terark
,
start_generation
=
2
,
suffix
=.
trk
)))
补充说明:
WiredTiger 会在 level0 和 level1 产生原生的 lsm-chunk, level2 及以上的层级才会产生 terark-chunk.在本测试中,完成 compact 后所有 chunk 都转为了 terark-chunk.这里的 bloom_filter 只作用于初期的 lsm-chunk 而不作用于 terark-chunk.
5.4. 测试用例
压缩率在上面已经对比很明显了,对于不同用例下,压缩率是不变的(23 GB vs. 62 GB).
剩下的测试主要是在给定时间内,重复进行随机访问.
key 提取于原文件,保证查询都会命中.这里要说明的是,key 文件有 1.2G 大小,因为是同一台机子上测试,可以认为测试程序自身会占用约 2G 大小的空间.
限制内存方面,
原生 wiredtiger 通过设置内核参数,以限制物理内存的方式完成;
适配了 terark 的经由 cgroup 完成;
二者方式不同在于原生 wiredtiger 间接使用的系统缓存是无法通过 cgroup 限制的.
5.4.1. 不限内存
不限制内存的情况下,原生WT会使用非常多的内存,实际场景中几乎不存在数据能全部装入内存的情况.
原生WiredTiger(约100万QPS):
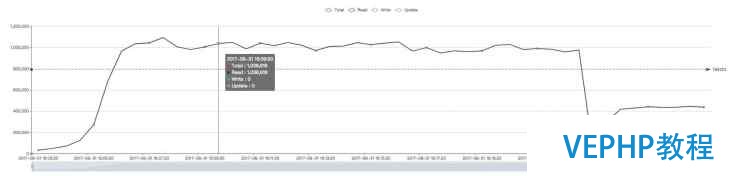
修改版WiredTiger(约122万QPS):
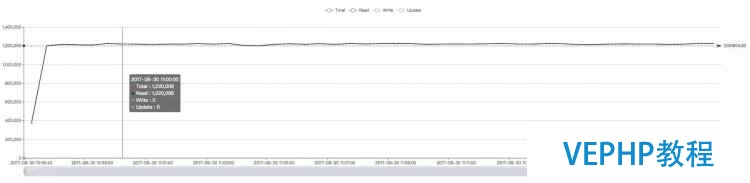
注:Terark 版本的波动很小是因为初始时有内存预热,数据驻留在内存后不会 eviction.
5.4.2. 内存限制 27G
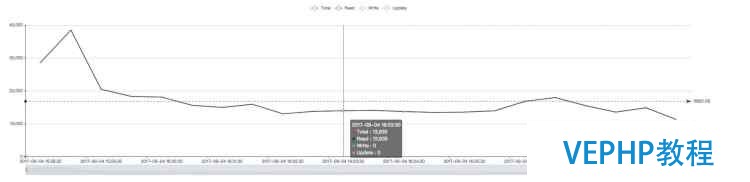
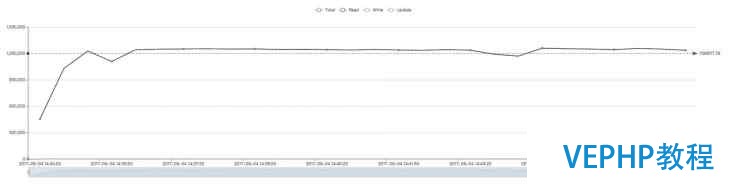
在这种情况下,Terark 版的 WT 可以完全装入内存,而原生的对内存需求太大,无法完全装入,性能差距明显(此时 Terark 版本的数据总尺寸约为 23 GB)
原生 WiredTiger(约1.3万):
修改版 WiredTiger (和不限内存保持一致,即122万左右):
5.4.3. 内存限制为12G
注:鉴于 terark 生成的数据集大小 23G,12G 的测试就是为了测试当数据集大于内存时的效果.
原生 WiredTiger(约6700):
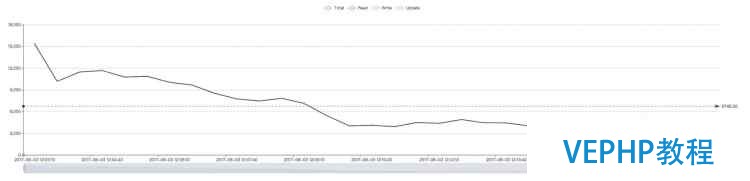
此处原本的 WiredTiger 在 12G 内存下和 27G 下的性能曲线都是先高后低.
我们的理解是初期 WiredTiger 的 DBCache 还未填满(默认值是物理内存的一半),这部分内存就被系统缓存用了,从而大量的已压缩数据块存在于系统缓存中,系统缓存的命中率就比较高,从而性能较好.
随着时间的推进,wiredtiger 不断申请新的内存,系统会牺牲系统缓存,优先保证进程的内存要求,直到把 DBCache 填满(达到 DBCache 上限,即物理内存的一半),此时 DBCache 内有大量已解压的数据,在相同的内存中,存放压缩的数据和已解压的数据,已解压的数据必然只能存放得更少,而系统缓存中有没有多少存量,从而整体上减小了 Cache 命中率,进而频繁的 IO 导致曲线转而向下.
这也说明在 IO 能力不足时,增大系统缓存比增大 DBCache 更能获得性能的提升,我们相信,如果这里使用的是 PCIe 的高端 SSD,情况会很不一样.
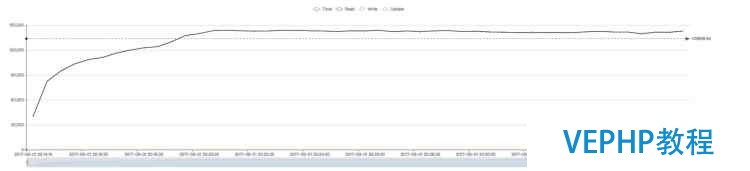
修改版 WiredTiger(约14万):
6.
总结
目前和 MongoDB 官方的合作还在继续,我们期待未来 MongoDB 的用户能够使用上 Terark 的技术,在 OLTP 领域能够获得更好的性能,更低的成本.
同时也非常期待能够和其他数据库厂商产生深度合作,把中国的技术推向世界.

Terark 专注于存储引擎的研发
提供领先的数据库和存储系统优化服务
搜索 "Terark" 了解更多
联系我们:contact@terark.com

Terark 实 验 室
